

Editor’s note (2025): This guide was originally published in 2021 and updated in September 2025. We kept the original breakdown as the basis and layered in clearly marked 2025 updates, bringing this guide up to date with the latest developments in music recommender systems.
This article gets into detail on how the Spotify recommender system works, outlining the process Spotify’s recommender follows to understand assets and users on the platform. If you're curious to find out more about how artists and their teams can influence the recommender system to optimize algorithmic traffic, check out our series on Recommender System Optimization.
As we move ahead into the 2020s, an ever‑increasing share of music consumption and discovery is mediated by AI‑driven recommendation systems. Back in 2020, as much as 62% of consumers rated platforms like Spotify and YouTube among their top sources of music discovery — and a healthy chunk of that discovery is mediated by recommender systems. On Spotify, for instance, over one third of all new artist discoveries happen through "Made for You" recommendation sessions according to the Made to be Found report.
Yet, as algorithmic recommendations take center stage in the music discovery landscape, the professional community at large still views these recommender algorithms as black boxes. Music professionals rely on recommender systems across platforms like Spotify and YouTube to amplify ad budgets, connect with new audiences, and execute successful release campaigns — while often lacking a clear vision of how these systems operate and how to leverage them to amplify artist discovery.
The topic of decoding AI‑driven systems is a key focus for Music Tomorrow. It is why we’ve built our first solution for music recommendation transparency — providing professionals and artists with insight into how their music is positioned within the streaming recommendation landscape. Our goal? Clearly showcase where a given artist sits in terms of Spotify's "algorithmic map", identify key artist, genre and thematic connections driving their algorithmic exposure, and suggest streaming audiences that can be leveraged to expand their algorithmic reach.
Every new user who joins our platform gets one free credit they can use to request an analysis on any artist with a Spotify page. So, if you’ve been looking to understand how your music is discovered on Spotify, and what steps you can take to unlock the algorithmic potential of your releases and make sure they’re recommended to the right crowds — sign up today to claim your free credit.
How do Spotify Recommendation Algorithms Work?
At its core, Spotify's recommendation engine is dealing with the same challenge as any other recommendation system out there (think TikTok "For You" algorithm, Netflix show suggestions, or Amazon marketplace product recommendations). All of these systems are matchmakers between creators and users in a two‑sided marketplace — trying to put the right items in front of the right users at the right time. All of them are optimized for similar business goals: user retention, time spent on the platform, and, ultimately, generated revenue. In order to achieve these goals, these systems need to understand the items they recommend — and the users they recommend them to. So, in Spotify’s case, it’s all about generating track representations and combining them with user taste models.
Let’s break down how the algorithms get there — starting with how the recommender ingests, analyzes, and qualifies the ever‑increasing body of music available on the platform. Spotify’s approach to track representation has two main components:
- Content‑based filtering, aiming to describe the track by examining the content itself (and, increasingly, the semantic landscape around it).
- Collaborative filtering, aiming to describe the track in its connections with other tracks on the platform.
The recommendation engine needs data generated by both methods to get a holistic view of the content on the platform and help solve cold‑start problems when dealing with newly uploaded tracks. First, let's take a look at the content‑based filtering algorithms.
How Spotify Understands Music: Content‑Based Filtering
Analyzing artist‑sourced metadata
As soon as Spotify ingests a new track, an algorithm will analyze all the general song metadata provided by the distributor and metadata specific to Spotify (sourced through the Spotify for Artists pitch form). In the ideal scenario, where all the metadata is filled correctly and makes its way to the Spotify database, this list should include:
- Track title
- Release title
- Artist name
- Featured artists
- Songwriter credits
- Producer credits
- Label
- Release date
- Genre & subgenre tags*
- Music culture tags*
- Mood tags*
- Style tags*
- Primary language*
- Instruments used throughout recording*
- Track typology (original / cover / remix / instrumental)
- Artist hometown/local market*
*Sourced through Spotify for Artists (S4A).
The artist‑sourced metadata is then passed downstream, as input into other content‑based models and the recommender system itself.
Analyzing raw audio signals
The second step of content‑based filtering is the raw audio analysis, which runs as soon as the audio files, accompanied by the artist‑sourced metadata, are ingested into Spotify's database. The precise way in which that analysis is carried out remains one of the "secret sauces" of the Spotify recommender system. Yet, here's what we know for sure — and what we can reasonably assume:
Let's begin with the concrete facts. The audio features data available through the Spotify API consists of metrics describing the sonic characteristics of the track. Many of these features have to do with objective sonic descriptions. For example, the metric of instrumentalness reflects the algorithm's confidence that the track has no vocals, scored on a scale from 0 to 1. However, on top of these "objective" audio attributes, Spotify generates at least three perceptual, high‑level features designed to reflect how the track sounds in a more holistic way:
- Danceability, describing how suitable a track is for dancing based on a combination of musical elements, including tempo, rhythm stability, beat strength, and overall regularity.
- Energy, representing "a perceptual measure of intensity and activity," based on the track's dynamic range, perceived loudness, timbre, onset rate, and general entropy.
- Valence, describing "the musical positiveness of the track." Generally speaking, tracks with high valence sound more positive (e.g., happy, cheerful, euphoric), while songs with low valence sound more negative (e.g., sad, depressed, angry).
Yet, these audio features are just the first component of Spotify's audio analysis system. In addition to audio feature extraction, a separate algorithm will also analyze the track's temporal structure and split the audio into different segments of varying granularity: from sections (defined by significant shifts in timbre or rhythm that highlight transitions between key parts of the track such as verse, chorus, bridge, solo, etc.) down to tatums (representing the smallest cognitively meaningful subdivision of the main beat).

Educated assumption: The combination of data generated by the audio analysis methods should allow Spotify to discern the audio characteristics of the song and follow their development throughout time and between different sections of the track. Furthermore, the audio features available publicly date back to circa 2013, reported as part of The Echo Nest audio analysis output (an audio intelligence company acquired by Spotify in 2014).
In the past ten‑plus years, audio analysis technologies have advanced significantly — which means that the audio features fed into the recommendation system today are likely much more granular than what's available through the public API. For instance, one of the research papers published by Spotify in 2021 states that audio features are passed into a model as a 42‑dimensional vector — which could mean that Spotify's audio analysis produces 42 different features (this is a research context, not necessarily production).
In addition, the company's research record details experiments with ML‑based source separation and pitch tracking & melody estimation. If these projects were to make it into production, that would mean the audio analysis system could slice the track into isolated instrumental parts, process them separately, and define melodies and chord progressions used throughout the composition.
In practice, all of the above would mean that Spotify’s audio analysis can define the recordings uploaded to the platform in great detail. The final output of the system might define the track along the lines of: “this song follows a V‑C‑V‑C‑B‑V‑C structure, builds up in energy towards the bridge, and features an aggressive, dissonant guitar solo that resolves into a more melancholic and calm outro.” Or even something much more detailed — the point is that, in all likelihood, Spotify's audio analysis can reverse‑engineer much of the track’s structure and extract a broad range of characteristics from the raw audio files. (Think of it as DAW‑level insight — metaphorically speaking.)
Now, back when we first published this article, the following section was titled Analyzing text with Natural Language Processing models — detailing how Spotify extracts semantic information from release-adjacent text sources, like lyrics, online press, artist bios and user-generated playlists names/descriptions. Now, the year is 2025 and OpenAI is valued somewhere between 150 and 300 billion, so a more appropriate title would be
Embedding the artist “Universe” with LLMs (Updated for 2025)
Modern systems don’t just parse text; they embed everything around a release—lyrics, cover art, canvases, short-form video, press, and social chatter—into a shared vector space. Those embeddings complement audio features and metadata, letting the system reason over both how the track sounds and where it culturally belongs. While specific production implementations vary across platforms, you could safely assume that most text and visual components of the release are used to power streaming recommenders.
If you’re curious about how that part of a system works, here’s an exercise you can try: take the lyrics of your latest release and plug them into a chatbot of your choosing, prompting it to extract the main themes and topics from the text, identify the song’s mood and genre, or even suggest when, where, and to whom that track should be recommended. Now imagine that instead of working off lyrics alone, that AI bot had access to all the information surrounding the release, from cover art to the latest comment under the artist’s post on Instagram.
It’s hard to know how deep that type of analysis actually goes, but here are some of the semantic data points likely to be leveraged by the system to generate track representations:
- Track lyrics
- Artist‑sourced text descriptions (S4A pitch, distributor contextuals, on‑platform bio)
- Visual components of the release (cover art, profile picture and banner, canvas, artist clips, music videos, etc.)
- Names and descriptions of user‑generated playlists featuring the release
- Chatter on social platforms (Reddit, X/Twitter, etc.) mentioning the release/artist
- Online media & music blog coverage
The three components outlined above — artist‑sourced metadata, audio analysis, and LLM‑based integrations — make up the content‑based part of the track‑representation approach within Spotify's recommender system. Yet, there’s one more key ingredient to Spotify's recipe for understanding music on the platform.
How Spotify Understands Music: Collaborative Filtering
In many ways, collaborative filtering has become synonymous with Spotify's recommender system. The DSP pioneered the application of this so‑called "Netflix approach" in music recommendation — and widely publicized collaborative filtering as the driving power behind its recommendation engine. So the chances are, you've heard the process laid out before, at least the following version of it:
"We can understand songs to recommend to a user by looking at what other users with similar tastes are listening to." So, the algorithm simply compares users' listening history: if user A has enjoyed songs X, Y, and Z, and user B has enjoyed songs X and Y (but hasn't heard song Z yet), we should recommend song Z to user B. By maintaining a massive user‑item interaction matrix covering all users and tracks on the platform, Spotify can tell if two songs are similar (if similar users listen to them) and if two users are similar (if they listen to the same songs).
Sounds like a perfect solution for music recommendation, doesn't it? In reality, however, this item‑user matrix approach comes with a host of issues that have to do with accuracy, scalability, speed, and cold‑start problems. So, Spotify has de‑emphasized pure consumption‑based filtering — instead, the current version of collaborative filtering focuses more on organizational similarity: i.e., "two songs are similar if a user puts them on the same playlist."
By studying playlist and listening‑session co‑occurrence, collaborative filtering algorithms access a deeper level of detail and capture well‑defined user signals. Simply put, streaming users often have broad and diverse listening profiles (in fact, building listening diversity is one of Spotify's priorities, as we've covered in our article on fairness in music recommender systems), and so the fact that a lot of users listen to song A and song B doesn't automatically mean these two artists are similar. After all, artists like Metallica and ABBA probably share quite a few listeners.
If, on the other hand, a lot of users put song A and song B on the same playlist — that is a much stronger sign that these two songs have something in common. On top of that, the playlist‑centric approach also offers insight into the context in which these two songs are similar — and with playlist creation being one of the most widespread user practices on the platform, Spotify has no shortage of collaborative‑filtering data to work through.
Reportedly, the Spotify collaborative‑filtering model is trained on a sample of ~700 million user‑generated playlists selected out of the much broader set of all user‑generated playlists on the platform. The main principle for choosing the playlists that make it into that sample? "Passion, care, love, and time users put into creating those playlists."
Now, we've arrived at the point where the combination of collaborative and content‑based models allows Spotify's recommender system to develop a holistic representation of each track. Next, the track profile is further enriched by synthesizing higher‑level descriptors (think of these as mood, genre, style tags, associated activities and social contexts, etc.) based on the collected data.
Music for Every Context and Every Occasion (Updated for 2025)
In the past few years we’ve seen a host of new recommender‑driven features rolled out — Spotify DJ, generative mix playlists (e.g., your sad acoustic punk mix), and a search bar that now enables intent‑based queries. To be able to support all of these features, Spotify had to ensure that all of them have a single source of truth to refer to — leading to a shift in the platform's approach to track representation.
In recent years, each track profile has become more like a complex structure built out of individual blocks. Tracks that are similar will share a lot of the same blocks, with each block encoding a specific feature. This means that algorithms down the road can easily pick apart that structure. That’s why you can now type a very specific idea into search (say, “new chill French instrumental hip‑hop track”) — and the system will have a good sense of what songs and albums to fetch.
But describing the music on the platform is just a part of the story. How does the system know what would be a good track to recommend to a specific user?
Generating User Taste Profiles
The approach to user profiling on Spotify is a bit simpler — essentially, the recommender engine logs all of the user's listening activity, split into separate context‑rich listening sessions. This context component is vital when interpreting user activity to inform recommendations. For instance, if the user engages with Spotify's "What's New" tab, the primary goal of the listening session is to quickly explore the latest releases added to the platform. In that context, high skip rates are to be expected — the user's primary goal is to skim through the feed and save some tracks for later — which means that a skip shouldn't be interpreted as a definite negative signal. If, on the other hand, the user skips a track from a "Deep Focus" playlist, it weighs in as a much stronger sign of dissatisfaction.
All the user feedback powering the system can be split into two primary categories:
- Explicit (active) feedback: library saves, playlist adds, shares, skips, click‑throughs to artist/album pages, artist follows, "downstream" plays.
- Implicit (passive) feedback: listening‑session length, playthrough, and repeat listens.
In the case of the Spotify recommender, explicit feedback weighs more for developing user profiles. Music is often consumed as off‑screen content, and so skipping tracks might not be your top priority — meaning that uninterrupted consumption doesn't always relate to enjoyment.
Next, all the user‑feedback data is processed to develop the user profile, defined in terms of:
- Most‑played and preferred songs and artists
- Saved songs and albums & followed artists
- Genre, mood, style, and era preferences
- Popularity and diversity preferences
- Temporal patterns
- Demographic & geolocation profile
Then the user taste profile is further subdivided based on the consumption context: i.e., the same user might prefer mellow indie‑pop on Sunday evenings and high‑energy motivational hip‑hop on Monday mornings. In the end, Spotify ends up with a context‑aware user profile that might look something like this:
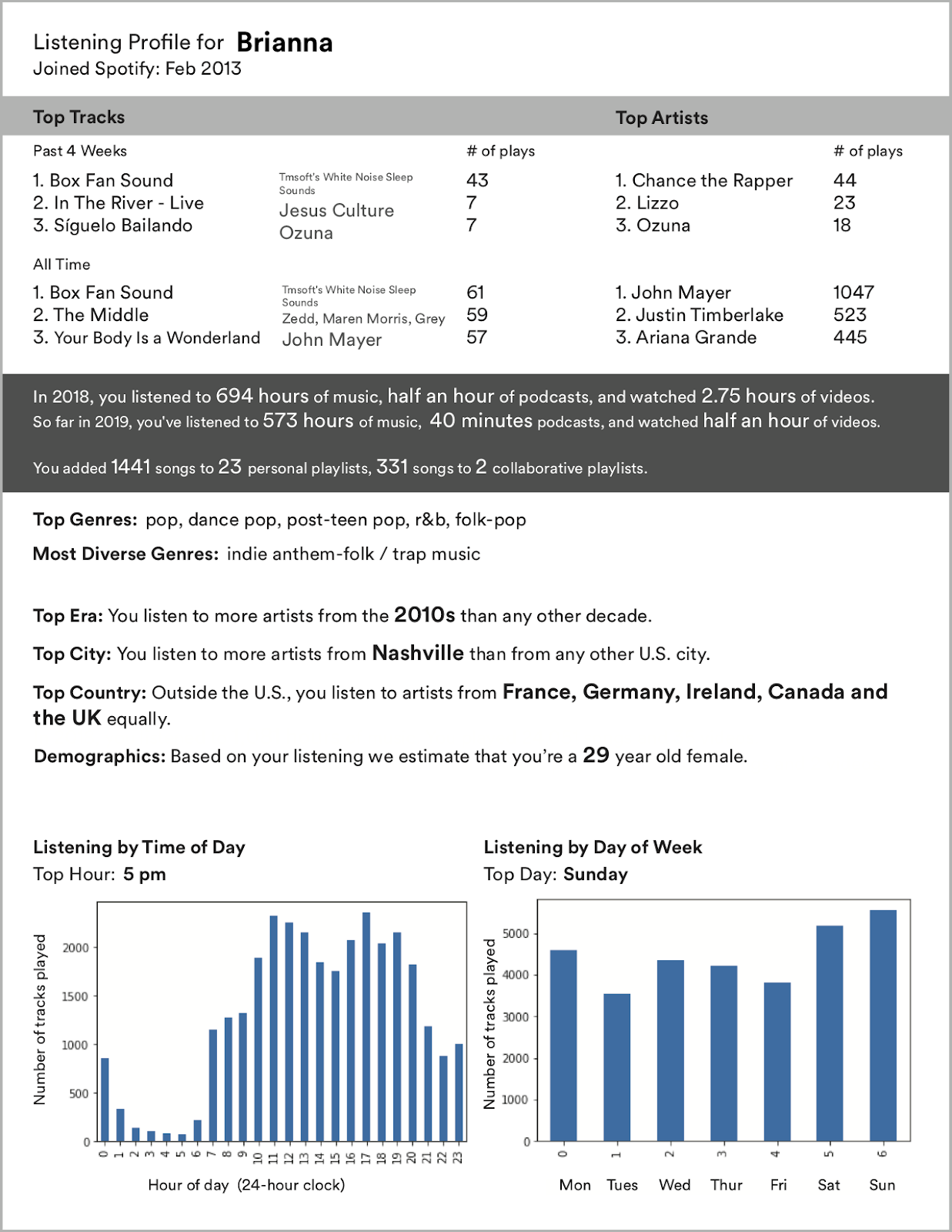
This history‑based user profile constantly develops and expands with fresh consumption and interaction data. Recent activity is also prioritized over historic profile: for instance, if the user gets into a new genre and it scores well in terms of feedback, the recommender system will try to serve more adjacent music — even if the user's all‑time favorites are widely different.
Modeling users across genres and contexts: multi‑interest taste clusters to replace a single profile (Updated for 2025)
When it comes to user modeling, it all comes down to one question: how do we get a deeper understanding of our users without leaving anyone behind? The improvements and data points introduced into the system must allow for better, more precise recommendations — but be applicable to most, if not all, users on the platform. Otherwise, you risk running a system that works great for some users but leaves the rest underserved.
One notable development trend is multi‑dimensional user profiling: rather than collapsing everything into one embedding, modern systems represent each listener with several long‑term interest embeddings (e.g., one capturing your preference for lo‑fi beats; another for contemporary jazz). These are learned by partitioning a user’s history into category‑aware subsequences and training separate representations per cluster. At serve time, a lightweight router picks the most relevant slots given context (time of day, device, entrypoint, etc.).
Another key trend is cross‑domain user profiling. Users don’t consume content in isolation — your music taste might relate to the movies you watch or the social media you engage with. Cross‑domain recommendation aims to leverage this, transferring learnings from one domain to another. In Spotify’s case, that means your favorite podcasts and audiobooks increasingly inform what songs you’re recommended. A challenge here, as mentioned earlier, is to do this without introducing user biases, and to ensure that single domain users — people who only engage with music on the platform — aren’t left out.
Recommending Music: Integrating User and Track Representations
Woooh. You've made it. The intertwined constellation of algorithms behind Spotify recommendations has produced the two core components — track and user representations — required to serve relevant music. Now, we just need the algorithm to make the perfect match between the two and find the right track for the right person (and the right moment).
Most large-scale recommenders follow a two-stage process: (1) candidate generation based on recommendation context and intent, followed by (2) ranking/re‑ranking to optimize for the current user & additional system goals.
However, the recommendation landscape on Spotify is much more diverse than on some of the other consumption platforms. Just consider the range of Spotify music features that are generated with the help of its recommendation engine:
- Discover Weekly & Release Radar playlists
- Your Daily Mix playlists
- Artist Mix playlists
- Generative Decade / Mood / Genre Mix playlists
- Special personalized playlists (Your Time Capsule, On Repeat, Repeat Rewind, Daily Drive, Daylist, etc.)
- Personalized editorial (algotorial) playlists
- Personalized Home/Browse section
- Personalized search results
- Playlist suggestions & Smart Shuffle
- Artist/track radio and autoplay features
- Spotify DJ
- “Discover” feed
All these diverse surfaces are powered by the recommender engine — but each of them is running on a separate algorithm with its own inner logic and reward system. The track and user representations form a universal foundation for these algorithms, providing a shared model layer designed to answer the common questions of feature‑specific algorithms, such as:
- User‑entity affinity: “How much does user X like artist A or track B? What are the favorite artists/tracks of user Y?”
- Item similarity: “How similar are artist A & artist B? What are the 10 tracks most similar to track C?”
- Item clustering: “How would we split these 50 tracks/artists into separate groups?”
The feature‑specific algorithms can tap into unified source models to generate recommendations optimized for a given consumption surface / user intent / consumption context. For instance, the algorithm behind Your Time Capsule would primarily engage with user‑entity affinity data to try and find tracks that users love but haven't listened to in a while. Discover Weekly algorithms, on the other hand, would employ a mix of affinity and similarity data to find tracks similar to the user's tastes, which they haven't heard yet. Finally, generating Your Daily Mix playlists would involve all three methods — first clustering the user's preferences into several groups and then expanding these lists with similar tracks.
The Goals and Rewards of Spotify’s Recommendation Algorithms
As mentioned at the beginning of this breakdown, the overarching goal of the Spotify recommender system has to do with retention, time spent on the platform, user satisfaction and, ultimately, generated revenue. However, these top‑level goals are way too broad to devise a balanced reward system for ML algorithms serving content recommendations across a variety of features and contexts — and so the definition of success for the algorithms largely depends on where and why the user engages with the system.
For instance, the success of the autoplay queue features is defined mainly in terms of user engagement — explicit/implicit feedback of listen‑through and skip rates, library and playlist saves, click‑throughs to the artist profile and/or album, shares, and so on. In the case of Release Radar, however, the rewards would be widely different, as users often skim through the playlist rather than listen to it from cover to cover. So, instead of studying engagement alone, the algorithms would optimize for long‑term feature retention and feature‑specific behavior: “Users are satisfied with the feature if they keep coming back to it every week; users are satisfied with Release Radar if they save tracks to their playlists or libraries.”
Finally, in some cases, Spotify employs yet another set of algorithms just to devise the reward functions for a specific feature. For example, Spotify has trained a separate ML model to predict user satisfaction with Discover Weekly (with the training set sourced by user surveys). This model would look at the entire wealth of user interaction data, past Discover Weekly behavior, and user goal clusters (i.e., if the user engaged with Discover Weekly as background, to search for new music, save music for later, etc.) — and then produce a unified satisfaction metric based on all that activity.
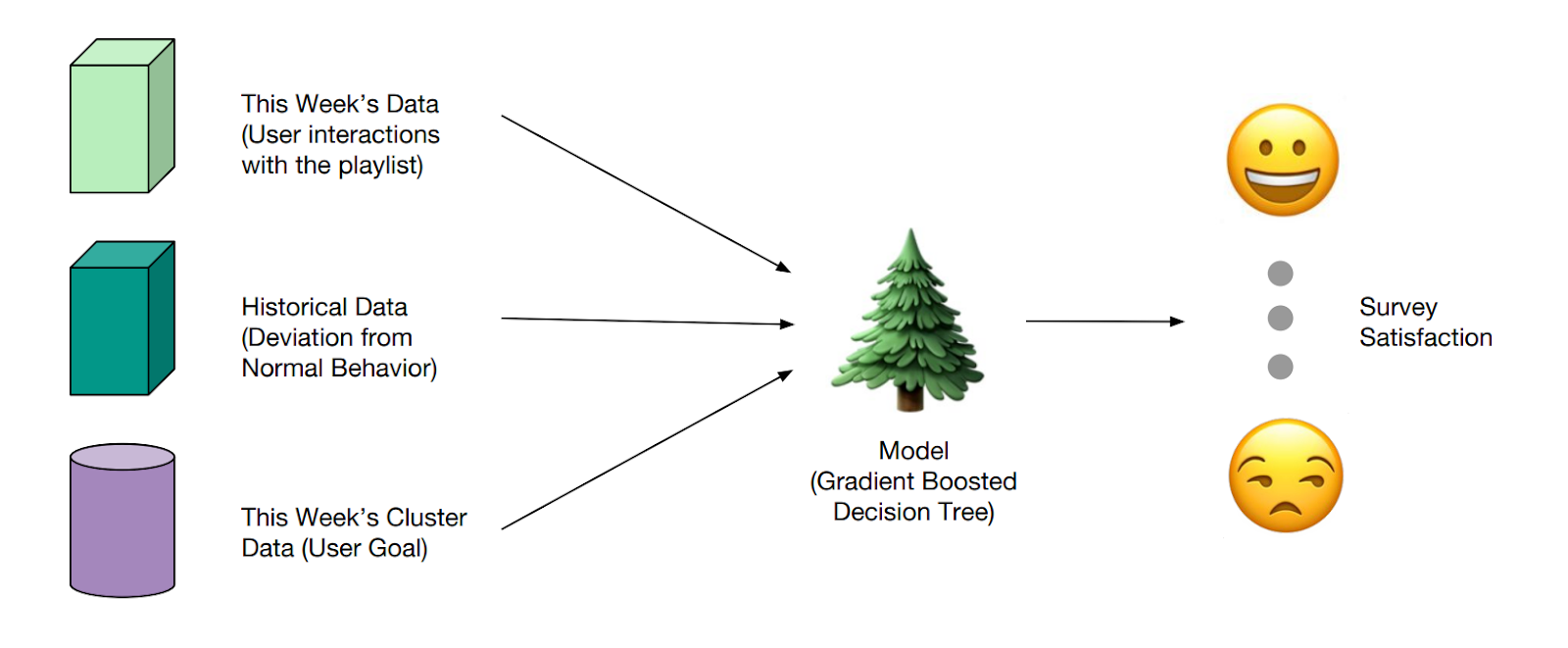
The satisfaction prediction produced by the model is then, in turn, used as the reward for the algorithm that composes Discover Weekly playlists, building a comprehensive reward system that doesn't rely on siloed, potentially ambiguous user signals.
What Artists Can Do To Get Recommended on Spotify?
Spotify’s recommender system is an extremely complex and intricate mechanism, with dozens (if not hundreds) of independent algorithms, AI agents, and ML models employed across various levels — all working together to create one of the most advanced recommendation experiences on the music streaming market. This system has been developed and iterated on for close to twenty years now — growing in size, capabilities, and complexity. But it’s far from unexplainable — even without having direct documentation describing all the secret ingredients, we can get a good understanding of its main parts — and the governing principles behind them.
From the artist’s standpoint, it is possible to use that knowledge to optimize the artist's profile within that recommender system. A meaningful, well‑educated algorithmic strategy could maximize the artist’s discoverability through algorithmic playlists and other recommendation surfaces — making sure engine serves the music to the right audiences, amplifying engagement, and helping turn casual listeners into fans.
But how would you go about it? We’ve spent the last few years focusing on this very question, and building music’s first data platform for recommender system optimization & transparency. If you’d like to learn more about our tools and approach, check out our dedicated RSO series or optimization case studies — but for those looking for a TL;DR answer, here’s one:
A Quick Artist Guide for Getting Recommended on Spotify
1) Before release: set the table
- Find your algorithmic targets — define scenes, genres, intents, moods, contexts and audiences to prioritize in your campaign
- Nail metadata hygiene (titles, moods, genres, language) and on-platform visuals
- Optimize your streaming profiles — make sure you leverage all the features and tick every box. Upload and sync lyrics, create unique canvases and artist clips, etc.
2) Release week: win the first sessions
- Target high-quality audiences aligned with your algorithmic targets
- Drive saves, shares playlist adds, and completes
- Use playlists featuring artist peers to expand the universe and maximize shared listenership
3) Sustain & grow: reinforce the signal
- Stay consistent in your targets and re-engage — platform tools like Marquee are great for retargeting, but should be used strategically, quality > quantity
- Follow up with rich content (remixes, music videos, etc.)
- Get on playlists — but make sure they’re aligned with algorithmic targets
- Release on a predictable cadence; stay consistent with your targeting if future tracks align.
4) Avoid at all costs:
- Fake streams and vanity campaigns that generate poor session feedback.
- Spray-and-pray targeting or playlisting pitching campaigns that generate sporadic signals.
Use Music Tomorrow to make it actionable.
Map your algorithmic landscape, and get access artist reports with deep audience insigths for digital ads targeting, target playlists for pitching, plus a tailored metadata & Spotify feature checklist. New users get one free credit to analyze any artist with a Spotify page.












